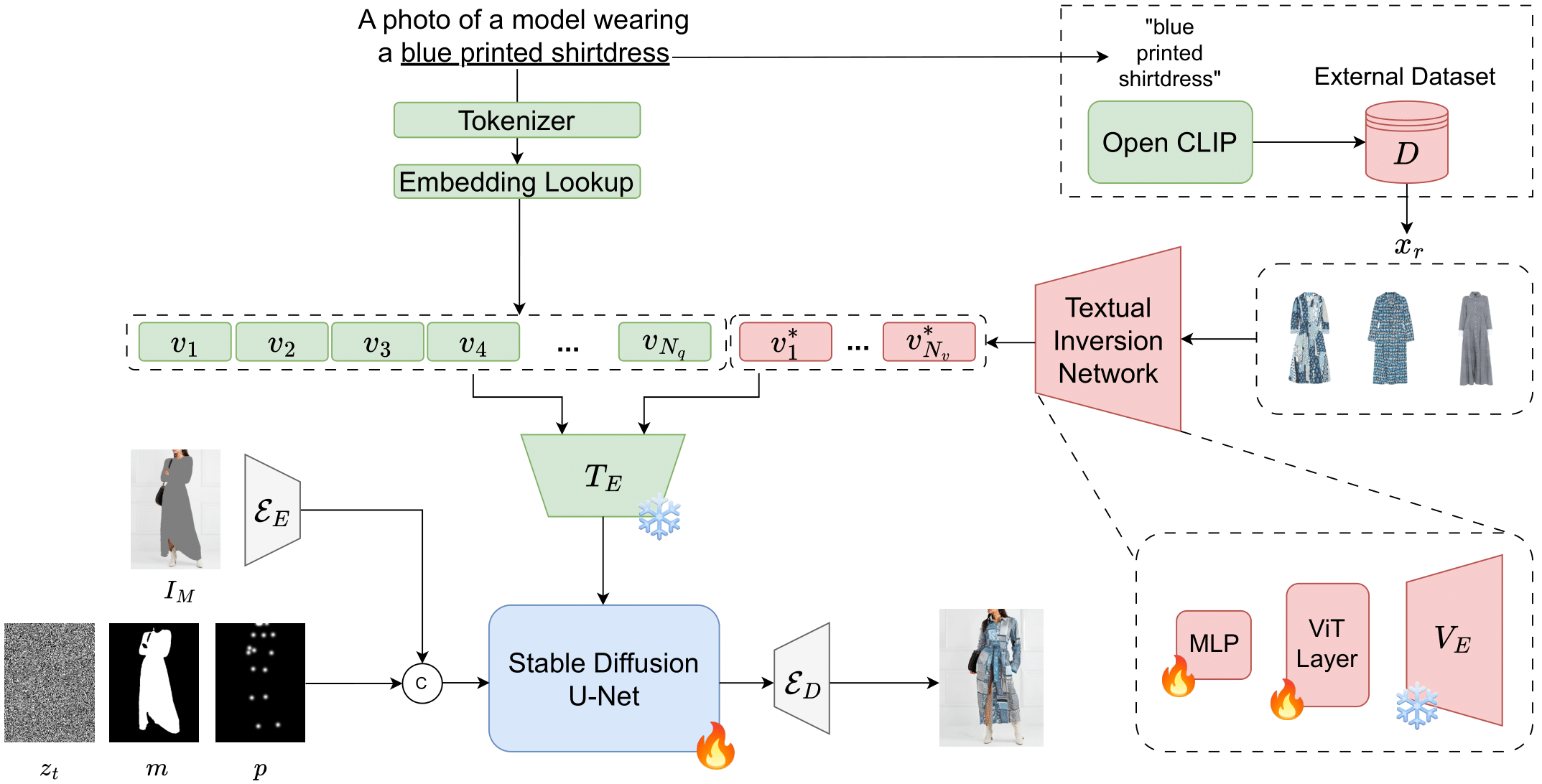
In recent years, the fashion industry has increasingly adopted AI technologies to enhance customer experience, driven by the proliferation of e-commerce platforms and virtual applications. Among the various tasks, virtual try-on and multimodal fashion image editing -- which utilizes diverse input modalities such as text, garment sketches, and body poses -- have become a key area of research. Diffusion models have emerged as a leading approach for such generative tasks, offering superior image quality and diversity. However, most existing virtual try-on methods rely on having a specific garment input, which is often impractical in real-world scenarios where users may only provide textual specifications. To address this limitation, in this work we introduce Fashion Retrieval-Augmented Generation (Fashion-RAG), a novel method that enables the customization of fashion items based on user preferences provided in textual form. Our approach retrieves multiple garments that match the input specifications and generates a personalized image by incorporating attributes from the retrieved items. To achieve this, we employ textual inversion techniques, where retrieved garment images are projected into the textual embedding space of the Stable Diffusion text encoder, allowing seamless integration of retrieved elements into the generative process. Experimental results on the Dress Code dataset demonstrate that Fashion-RAG outperforms existing methods both qualitatively and quantitatively, effectively capturing fine-grained visual details from retrieved garments. To the best of our knowledge, this is the first work to introduce a retrieval-augmented generation approach specifically tailored for multimodal fashion image editing.


@inproceedings{sanguigni2025ijcnn,
title={Fashion-RAG: Multimodal Fashion Image Editing via Retrieval-Augmented Generation},
author={Sanguigni, Fulvio et al.},
booktitle={2025 International Joint Conference on Neural Networks (IJCNN)},
year={2025},
organization={IEEE},
}